
ESnet’s research and development activities are integral to our mission of advancing the capabilities of today’s networking technologies to better serve the science requirements of the future. We continually investigate, create, develop, and test the services, protocols, routing techniques, and tools necessary to meet the expanding needs of our user community of DOE scientists.
Using Telemetry to Drive High-Touch Services
Being able to identify the kinds of data flowing across the network, and to and from whom, will allow ESnet to optimize future workflows and services. ESnet’s High-Touch project provides new data and insights through the use of programmable hardware (Field Programmable Gate Arrays, or “FPGA”) and software. The first class of these services offers network telemetry at both the flow and packet levels at multi-100GE speeds, improving visibility into traffic for network engineering, cybersecurity, and networking research.
In 2022, ESnet demonstrated a “code complete” system implementation for providing unsampled flow data using a prototype server configuration installed in two ESnet locations. The demonstration showed the improved insights made possible by examining unsampled packet data instead of the sampled or aggregated data that is the
norm for technologies commonly available today. Some initial analysis of data gathered from the prototype deployment has led to performance enhancements and improvements in the fidelity of the captured data.
This work, combined with engagement with internal ESnet customers (particularly in network engineering and cybersecurity), will drive future applications built with the base data collection capabilities and data analysis. Deployment of production High-Touch servers with FPGA hardware into the ESnet6 production network began in late CY2022. When completed, two High-Touch servers will be installed at more than 40 ESnet locations, allowing visibility of all traffic entering or exiting the ESnet backbone.
Applying Good SENSE to Workflows
SENSE (SDN for End-to-End Networking @ Exascale) is a multi-network ESnet orchestration and intelligence system providing programmatic-driven networked services to domain science workflows. These services can span multiple domains/sites and be presented to different workflows in a highly customized manner. The SENSE services are referred to as “networked services” because, in addition to the network elements, SENSE can orchestrate compute and storage elements that connect to the network, such as DTNs, Cloud compute, and site-managed network resources.
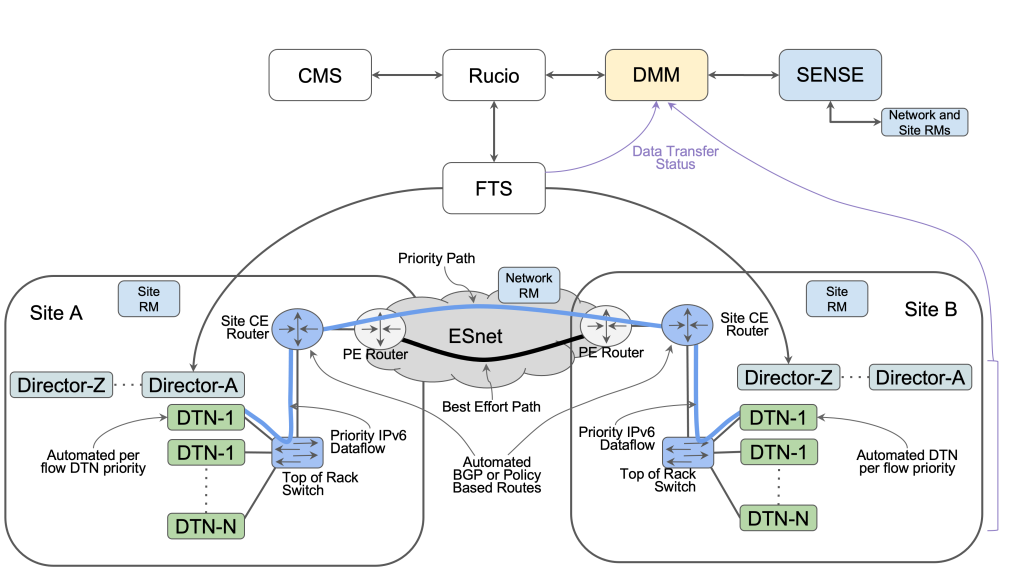
A key objective of the SENSE system is to allow the workflows to access the network in a manner that best facilitates their objectives. A prototype system was deployed in 2022 at UC San Diego and Caltech, where Large Hadron Collider (LHC) Tier 2 facilities are hosted. In addition, SENSE is being integrated into LHC Compact Muon Solenoid (CMS) workflows that use the Rucio/FTS/XRootD data management and movement system. Although the CMS compute system management provides deterministic resources for individual users, the data transfers and associated network services are unpredictable. By integrating SENSE services, Rucio can identify the dataflow groups that should have a higher priority, which influences network provisioning. ESnet’s presentation at the SC22 conference demonstrated this interoperation with SENSE; testing/development is ongoing as part of the CMS experiment support.
Sewing FABRIC Together: A National-Scale Programmable Experimental Network Infrastructure
Funded by the National Science Foundation’s (NSF’s) Mid-Scale Research Infrastructure program, FABRIC is a novel adaptive programmable national research network testbed that allows computer science and networking researchers to develop and test innovative architectures that could yield a faster, more secure Internet. (The acronym FABRIC is Adaptive ProgrammaBle Research Infrastructure for Computer Science and Science Applications.)
FABRIC collaborators include the University of North Carolina Renaissance Computing Institute (RENCI), the University of Illinois Urbana Champaign, the University of Kentucky, Clemson University, and ESnet. An operational national-scale testbed is slated to be unveiled in October of 2023. FABRIC is built on the ESnet6 fiber footprint, and for this effort, ESnet provided engineering and operational support to deploy the FABRIC nodes nationwide (and for FABRIC Across Border internationally). In addition, ESnet supplied consulting to finalize aspects of the experiment infrastructure, including security; formalized operational roles and procedures for production support; co-authored (with RENCI) the FABRIC Network Service Model; and convened the Science Advisory Committee.
ESnet also contributed software development to the project, including a new family of Layer-3 network service to the FABRIC Control Framework, a tool-based federation across multiple testbeds (e.g., FABRIC, Chameleon, and SENSE testbeds), support for Cloud connect services for FABRIC experimenters, and the implementation of an automated process to add external facilities interconnecting the various FABRIC sites.
FABRIC Across Borders (FAB)
As part of this project, ESnet assists with the international node deployments, networking to the core FABRIC network, and working with international teams of researchers to develop advanced domain science workflows in the form of experiments on the combined FABRIC and FAB infrastructure. ESnet staff also continued to lead the connectivity planning for the CERN site deployment and to support experimenter coordination and connectivity requirements for LSST
and CMB-S4.
Funded by the NSF’s International Research and Education Network Connections (IRNC), the FABRIC Across Borders (FAB) project seeks to deploy four FABRIC nodes at the University of Bristol (UK), CERN (Switzerland), University of Amsterdam (The Netherlands), and University of Tokyo (Japan).
At the Crossroads for the Self-Driving Network with AI Engine Hecate
Imagine a “self-driving network” that combines telemetry, automation, dev-ops, and machine learning to create an infrastructure that is responsive, adaptive, and predictive on the fly. Such a network will require an amalgamation of multiple AI capabilities integrated with the networking infrastructure that can perform various functions to improve network aspects such as performance and traffic engineering.
Scientific research networks pose specific traffic engineering problems:
- Large science traffic flows are often random, peaking when large facilities run or have multiple spontaneous large data transfers.
- Science traffic exhibits high variability, encompassing diverse performance requirements such as deadline-driven transfers, low-latency transfers, and long-lived flows that often clog up the network
- Network performance is extremely critical in preventing loss. Losing packets can seriously jeopardize the integrity of science results.
The primary goal for network optimization is to ensure the best possible network design and performance while minimizing the total cost. In networks designed to support science, optimizing network performance
involves minimizing packet loss and optimizing for both high and low-latency traffic.
A patent for Hecate was filed in November 2022 — “Autonomous Traffic (Self-Driving) Network with Traffic Classes and Passive/Active Learning” — and is pending. The technology can be licensed through Berkeley Lab’s Intellectual Property Office.
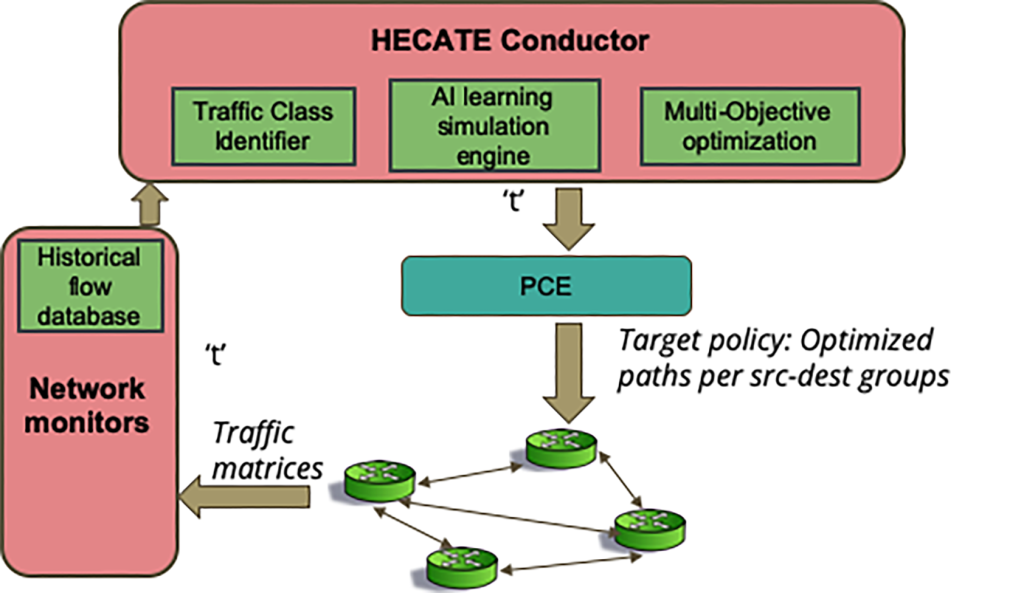
Led by ESnet Planning & Innovation researchers and named for the Greek goddess of the crossroads, Hecate is an AI engine that tackles the traffic engineering component. ESnet’s experience in developing graph neural networks (GNNs) to help predict WAN traffic shows that networks, modeled as graphs, produce more accurate predictions than traditional techniques. The team used machine learning to recognize traffic patterns and perform path finding using real-time network telemetry (i.e., network health telemetry data including latency, utilization, and loss), for packet route calculation and real-time dynamic path optimization.
Using In-Network Data Caching to Reduce Traffic Volume
In large scientific collaborations, multiple researchers frequently need access to the same set of files for various analyses. This results in repeated interactions with large amounts of shared data that are located at considerable distance. These data interactions have high latency due to distance and consume the limited bandwidth available on the WAN. To address this, ESnet installed regional data storage caches as a new networking service to reduce the WAN traffic and data access latency.
In CY2022, ESnet collaborated with LHC’s high-energy physics experiment, CMS, to gain insight into networking characteristics and the predictability of network utilization. These insights encompassed network traffic reduction, data throughput performance, and more. ESnet aimed to understand the predictability of network utilization to assist in planning for the deployment of additional in-network caches in the science network infrastructure. By exploring about 3 TB of operational logs, we observed that, on an average day, this cache removed 67.6% of file requests from the wide-area network and reduced the traffic volume on the widearea network by 12.3TB (or 35.4%). ESnet developed and tested a machine learning model that can accurately predict the cache accesses, cache misses, and network throughput, making the model useful for future studies on resource provisioning and planning. It also deployed two additional caching nodes in Chicago and Boston. Additional deployments and comparative study to better understand in-network caches are planned for CY2023.
Janus Framework Enables DTN-as-a-Service
Data transfer nodes (DTNs) are hosts specifically designed to optimize data transfers. ESnet’s Advanced Technologies and Testbed Group has developed the DTN-as-a-Service (DTNaaS) model that explores the concept of a managed data movement service platform that can stage and move data across a wide area within a well-defined and dynamic core network. The model focuses on a prototype controller implementation and automated packaging of DTN transfer software (e.g., Globus) while also seeking to develop a robust framework able to accommodate the many types of software containers that require flexible deployment strategies. The result is the DTNaaS model Janus, a lightweight orchestration framework built around exposing container configuration and tuning specifically for high-performance data mover applications.
By specializing the feature set of the framework, Janus reduces complexity and offers a path to rapid, optimized deployment for common DTN hardware patterns. In particular, Janus addresses a common DTN requirement for multiple, high-speed network attachments in containers with IPv4/IPv6 dual-stack configurations. Janus’s deployment for in-network caching, the ESnet testbed, the FABRIC software federation, and ESnet community DTNs necessitated several capability upgrades in the underlying software in 2022. Janus now successfully manages the container images and dual-homed container network attachments on the caching nodes at ESnet’s Chicago and Boston sites. Based on these and other successes, the original caching pilot node at Sunnyvale has also begun the process of transitioning to the Janus/DTNaaS deployment model.
EJ-FAT: Real-Time DSP Processing for Edge Compute
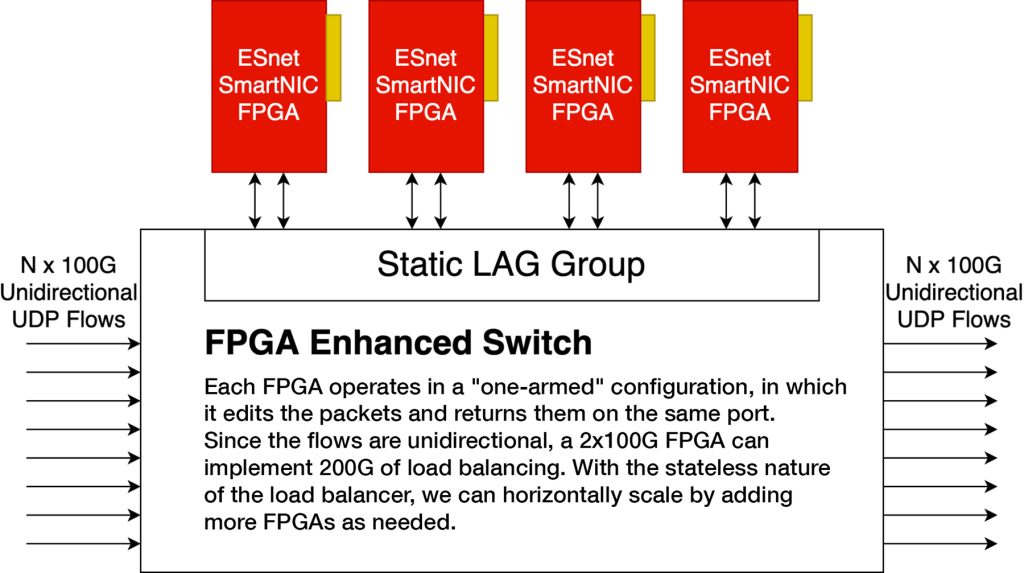
The DOE’s particle accelerators, x-ray light sources, electron microscopes, and other large science facilities are instrumented with many high-speed data acquisition systems (DAQs) that can produce multiple 100 Gbps data streams for recording and processing. This processing is conducted on large banks of compute nodes in local and remote data facilities. To increase the ability to integrate these experiments with high performance computing (HPC) centers, in CY2022 ESnet collaborated with the Thomas Jefferson National Accelerator Facility (JLab) to develop a prototype real-time load balancer for distributing UDP-encapsulated DAQ payloads into a dynamically allocated set of compute elements.
Named EJ-FAT — for ESnet JLab FPGA Accelerated Transport — the load balancer was implemented using FPGA technology to achieve line rates in excess of 100 Gbps, and has successfully integrated with JLab’s ERSAP processing pipeline for end-to-end event processing. The entire workflow has been demonstrated to perform real-time, end-to-end DSP processing, at 100 Gbps.
Designed to support WAN latencies for geographically distributed accelerator facilities and HPC centers, EJ-FAT demonstrates that computing can be integrated with data acquisition without burdening the data acquisition hardware with the details of the computing environment.
Through streamlining the data acquisition system, this demonstrates the potential for computing to scale up both in terms of the number of compute nodes and in the sophistication of the computing design. This facilitates the utilization of remote computing for enhanced compute resiliency and enables experiments with high-speed DAQs that may not be able to deploy sufficient local computing resources to fully leverage some experimental modalities. EJ-FAT also makes it easier for a computing facility to host the processing for multiple accelerators or experiments, and facilitates researchers use of the best computing for their experiment configuration.
Designing the QUANT-NET Architecture and Control Plane
Today, quantum networks are in their infancy. Like the Internet, quantum networks are expected to undergo different stages of research and development until they reach practical functionality. Based on laws of quantum mechanics (such as superposition, entanglement, quantum measurement, and the no-cloning theorem), researchers are envisioning quantum networks with novel capabilities that could be transformative to science, the economy, national security, and more.
The Quantum Application Network Testbed for Novel Entanglement Technologies (QUANT-NET), a project funded by DOE/ASCR, brings together expertise and resources at UC Berkeley, the California Institute of Technology, and the University of Innsbruck to build a three-node distributed quantum computing testbed
between two sites, Berkeley Lab and UC Berkeley, connected with an entanglement swapping substrate over optical fiber and managed by a quantum network protocol stack. The team plans to demonstrate entanglement between small-scale ion trap quantum processors at both locations. On top of this capability, they will implement the most fundamental building block of distributed quantum computing by teleporting a controlled-NOT gate between two nodes.
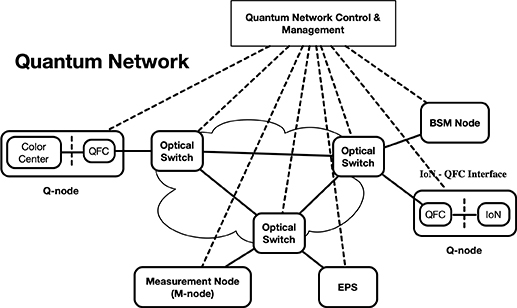
In 2022, QUANT-NET researchers made significant progress in the R&D areas of quantum testbed infrastructure, trapped-ion quantum technology, quantum frequency conversion R&D, color center quantum technologies, and QUANT-NET architecture and control plane. Also in 2022, ESnet’s quantum network research group completed an initial design of QUANT-NET’s architecture, utilizing a centralized control model that is modular, flexible, extensible, and deployable, as well as an initial design of the control plane.